

В последние годы нейронные сети стали неотъемлемой частью нашей жизни, и их использование в различных областях человеческой деятельности только расширяется. Музыка не стала исключением – нейронные сети активно используются для создания музыкальных композиций, обработки звука и даже для написания текстов песен. В этой статье мы рассмотрим различные музыкальные нейронные сети и их возможности.
Топ 10 нейросетей для создания музыки
AIVA
Magenta от Google
Jukebox
Flow Machines
Audiomentions
Coeur
MusicLM от Microsoft
MuseNet от OpenAI
E-MUSES от Sony
DeepMusic от NVIDIA
AIVA - это одна из первых музыкальных нейросетей, которая была создана для создания музыкальных композиций из текстовых запросов. Если вы хотите, чтобы нейросеть создала для вас, например, танцевальную музыку, просто введите запрос “танцевальная музыка”. AIVA также может обрабатывать другие запросы, такие как указание жанра, темпа или настроения.Magenta от Google - еще одна известная нейросеть, предназначенная для создания музыкальных произведений различных жанров и стилей. Magenta способна имитировать звучание разных инструментов, создавать сложные мелодии и гармонии, а также создавать уникальные музыкальные композиции.
Jukebox - нейросеть от того же Google, которая использует уже существующие музыкальные произведения для создания новых композиций. Вы выбираете несколько разных песен и Jukebox создает новое произведение, комбинируя элементы этих песен по своему усмотрению.
Flow Machines - нейросеть компании OpenAI, способная создавать музыкальные произведения разных стилей, начиная от джаза и заканчивая роком или поп музыкой.
Audiomentions - нейросеть, позволяющая создавать музыку на основе текстового запроса. Вы описываете настроение или тему своего музыкального произведения, а нейросеть создает музыку на основе данного описания.
Coeur - нейросеть разработки Meta (бывший Facebook), которая также создает музыкальные композиции различных жанров с использованием алгоритмов машинного обучения.MusicLM от Microsoft - данная модель способна генерировать музыкальные композиции в различных стилях и жанрах. MusicLM может создавать как простые мелодии, так и сложные музыкальные произведения.
MuseNet от OpenAI - эта нейросеть может создавать музыкальные композиции разных жанров и стилей, имитируя звучание различных музыкальных инструментов.
E-MUSES от Sony - еще один генератор музыкальных композиций, способный создавать музыку разных жанров. E-MUSES использует алгоритмы машинного обучения и может быть настроен на создание музыки с определенными характеристиками.
DeepMusic от NVIDIA - последняя в нашем списке, но не менее важная нейросеть. DeepMusic может создавать музыкальные композиции на основе заданных параметров, таких как жанр, настроение или стиль. Она также способна имитировать звучание музыкальных инструментов и создавать гармоничные мелодии.
Музыкальные нейросети стали важным инструментом для создания и обработки музыкальных композиций. С их помощью можно создавать уникальные музыкальные произведения, обрабатывать существующие треки и даже генерировать тексты песен. Эти технологии уже используются в различных музыкальных проектах и продолжают развиваться, чтобы стать еще более эффективными и универсальными.
Программа с открытым кодом для извлечения вокала из трека

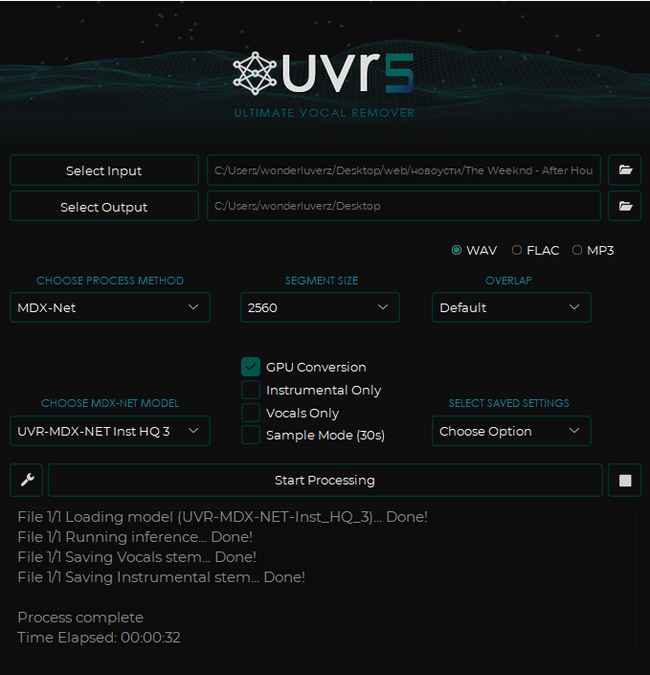
Всем привет! Сегодня Ultimate Vocal Remover GUI у нас на обзоре. Программа доступна на GitHub и установщиком, давайте посмотрим, на что она способна!
Я возьму три трека для пробы
DJ BoBo - Let The Dream Come True
Junior Caldera - Can't Fight This Feeling
The Weeknd - After Hours
Покажу работу на двух моделях, которые мне понравились больше всего - MDX-Net - очень качественно отделяет голос и Demucs - имеет возможность сплитнуть трек на 4 дороги - бас, ударные, мелодия и голос. Каждая хороша под свои задачи и как по мне эта программа справляется лучше онлайн-сервисов AI Splitter'a и Vocal Remover'а с их одной бесплатной попыткой. Кстати, пройдёмся по кнопкам и крутилкам внутри программы:

В окне Select Input выбираем файл с компьютера, с которым будем работать. Output соответственно выбираем куда сохранять
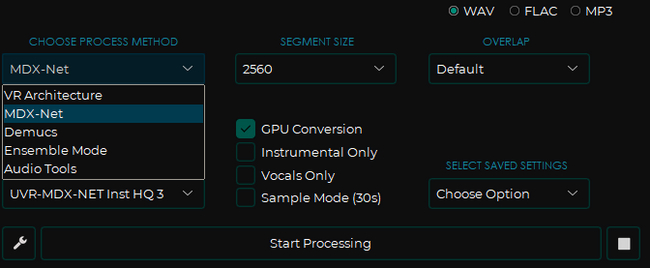
Choose process method - выбор модели. Вы можете поэкспериментировать, но, как я уже сказал, мне приглянулись две модели из этого списка.
В правом верхнем углу выбираем формат в который будем экспортировать.
Segment Size - вот тут сложнее. Как я понимаю - это что-то типа объёма буфера, что напрямую влияет на качество генерации. Я выставил 2560, но думаю можно и больше, но мне показалось этого более чем достаточно.
GPU Coversion - использовать графический процессор для более быстрого результат
Instrumentals/Vocal only - сохранить только вокал либо только инструментал
Sample Mode - для тех, кто хочет найти для себя лучшую модель - вместо полного трека демонстрирует 30-секундные отрывки с отделенным голосом
Overlap я поставил дефолтный. Вот кстати мои настройки для модели Demucs:
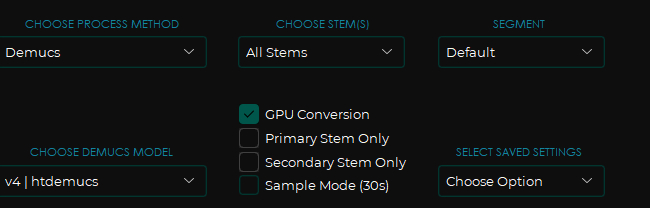
Давайте посмотрим на результат:
MDX-Net очень круто справилась с задачей, я думаю если выставить в Demucs буфер побольше то результат будет покруче!
До новых встреч, ждите новые гайды на классные нейросетевые штуки!
Интересна тема генерации музыки с помощью нейросетей? Добро пожаловать в Нейро-Звук🔉
Понравилось? Тогда милости прошу в мой телеграм канал, буду ждать тебя там!🔥

